
در بسیاری از صنایع، بازرسی بصری پیشرفته (Visual Inspection) قلب کنترل کیفیت محسوب میشود. تا همین چند سال پیش، دو روش عمده وجود داشت:
- بازرسی دستی توسط نیروی انسانی
- سیستمهای کلاسیک بینایی ماشین مبتنی بر قوانین ثابت و پردازش تصویری سنتی
این روشها تا زمانی که محصولات ساده، تیراژ پایین و تنوع کم بود، قابلقبول به نظر میرسیدند. اما امروز با واقعیتهایی روبهرو هستیم که این پارادایم را زیر سؤال میبرد:
- افزایش پیچیدگی محصولات: قطعات چندلایه، PCBهای با تراکم بالا، سطوح پیچیده، پوششهای ویژه و…
- تیراژ تولید بالا و سرعت زیاد خطوط: میلیثانیهها اهمیت دارند؛ خط نمیتواند منتظر اپراتور یا الگوریتمهای سنگین غیربهینه بماند.
- انتظار سطح کیفیت بسیار بالا: عیوب بسیار ریز هم ممکن است منجر به بازگشت محصول، خسارت مالی و آسیب به برند شود.
- کمبود نیروی ماهر برای بازرسی بصری دستی و خستگی، خطای انسانی و عدم ثبات در تصمیمگیریها.
در چنین شرایطی، یادگیری عمیق (Deep Learning) بهعنوان یک فناوری تحولآفرین وارد میدان شده است؛ سیستمی که میتواند از دادهها یاد بگیرد، خود را با پیچیدگی الگوهای بصری تطبیق دهد، و عیوبی را تشخیص دهد که برای چشم انسان یا روشهای کلاسیک تقریباً نامرئی هستند.
چرا پایش مونتاژ اهمیت حیاتی دارد؟
در بسیاری از صنایع، خطای مونتاژ فقط یک اشکال ظاهری نیست؛ میتواند به مواردی جدی مانند:
- خرابی عملکردی محصول
- افزایش نرخ برگشت کالا
- هزینههای گارانتی
- آسیب به اعتبار برند
- خطرات ایمنی برای کاربر نهایی
منجر شود.
برای مثال:
- در صنعت خودرو، جا نرفتن یک پیچ یا اتصال اشتباه یک قطعه میتواند عملکرد ایمنی را مختل کند.
- در الکترونیک، یک خازن یا کانکتور جاافتاده ممکن است کل برد را از کار بیندازد.
- در تجهیزات پزشکی، نقص مونتاژ حتی اگر جزئی باشد، میتواند غیرقابل قبول و بسیار خطرناک باشد.
- در لوازم خانگی، قطعهای که درست نصب نشده، ممکن است باعث نویز، نشتی، داغ شدن یا خرابی زودهنگام شود.
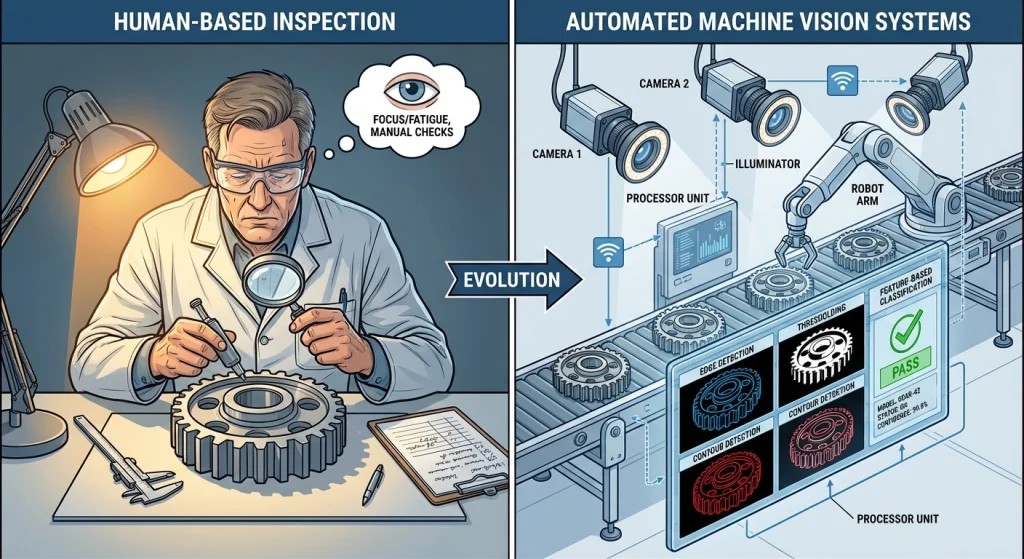
روشهای سنتی کنترل کیفیت، مثل بازرسی انسانی یا نمونهبرداری دورهای، هرچند هنوز مفیدند، اما محدودیتهای مهمی دارند:
- خستگی و خطای انسانی
- کندی در بازرسی
- عدم پوشش 100٪ محصولات
- وابستگی به مهارت اپراتور
- ناپایداری در شرایط نوری و محیطی
در مقابل، سیستمهای مبتنی بر پردازش تصویر میتوانند همه محصولات را، در لحظه، با معیارهای ثابت و دقیق بررسی کنند.

محدودیتهای سیستمهای کلاسیک بینایی ماشین (Rule-Based)
حساسیت شدید به تغییرات جزئی
- تغییر نور محیط
- تغییر زاویه قرارگیری قطعه
- تفاوتهای کوچک تولید که لزوماً عیب نیستند
مقیاسپذیر نبودن
- نیاز به قوانین جدید برای هر محصول
- وابستگی شدید به شرایط تولید
- هزینه نگهداری بالا
ناتوانی در درک الگوهای پیچیده
- عیوب بدون شکل مشخص
- عیوب ترکیبی بافت، رنگ و فرم
افزایش نرخ خطا
- False Positive → افزایش ضایعات
- False Negative → ریسک برای مشتری
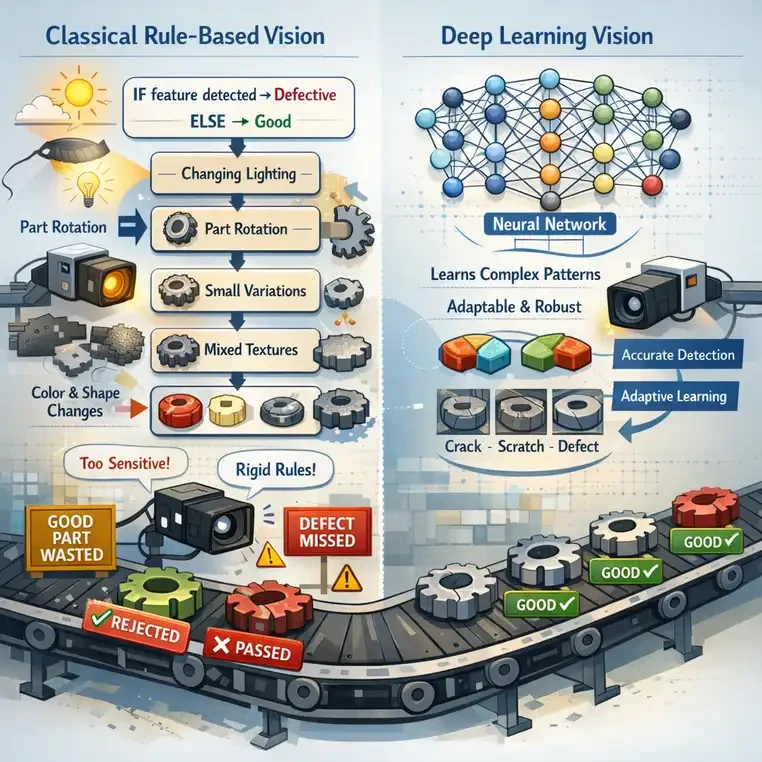
نقش یادگیری عمیق در انقلاب بینایی ماشین
بینایی ماشین کلاسیک
پیش از موج یادگیری عمیق:
- Handcrafted Features: SIFT، SURF، HOG، LBP
- Traditional Classifiers: SVM، Random Forest، KNN
محدودیتها:
- نیاز به طراحی دستی ویژگی برای هر مسئله
- حساسیت بالا به نور و زاویه
- ضعف در تشخیص عیوب بسیار ظریف
Deep Learning (CNN)
تحول در بازرسی بصری پیشرفته:
- یادگیری خودکار Featureها
- انتزاع از سطح پیکسل تا الگوهای پیچیده
- عملکرد بسیار بهتر روی دادههای بزرگ
موارد قابل تشخیص:
- Micro-cracks
- خراشهای با کنتراست کم
- تغییر بافت سطح
- نقص در پرینت، لحیمکاری، جوش
- عیوب ترکیبی (فرم + رنگ + بافت)
دقتی نزدیک یا حتی بالاتر از اپراتور انسانی — در سرعتی که انسان قادر به انجام آن نیست.
معماریهای کلیدی در تشخیص عیوب پیچیده
شبکههای کانولوشنی (CNN)
CNNها هسته بسیاری از سیستمهای بازرسی صنعتی هستند، چون:
- روی دادههای تصویری بهینه شدهاند.
- نسبتاً کارآمدند و روی سختافزارهای Embedded یا GPUهای سبک هم قابل اجرا هستند.
چند الگوی معماری رایج:
- شبکههای کلاسیک: مثل ResNet، VGG، DenseNet
- مناسب برای طبقهبندی سالم/معیوب یا نوع عیب
- U-Net و مشتقات آن:
- برای سگمنتیشن عیوب روی تصویر (یعنی مشخص کردن دقیق ناحیه عیب)
- FPN، Mask R-CNN، YOLO و… برای تشخیص عیب بهصورت Object Detection
- وقتی میخواهید مکان عیب (Bounding Box / Mask) را روی قطعه مشخص کنید.
CNNها در تشخیص عیوب سطحی با الگوهای قابل مشاهده، بسیار قویاند. اما وقتی پیچیدگی فضایی و ساختاری بالا میرود – یا روابط بلندبرد (Long-range dependencies) مهم میشوند – معماریهای Attention محور وارد بازی میشوند.

CNNها هسته بسیاری از سیستمهای بازرسی صنعتی هستند، چون:
- روی دادههای تصویری بهینه شدهاند.
- نسبتاً کارآمدند و روی سختافزارهای Embedded یا GPUهای سبک هم قابل اجرا هستند.
چند الگوی معماری رایج:
- شبکههای کلاسیک: مثل ResNet، VGG، DenseNet
- مناسب برای طبقهبندی سالم/معیوب یا نوع عیب
- U-Net و مشتقات آن:
- برای سگمنتیشن عیوب روی تصویر (یعنی مشخص کردن دقیق ناحیه عیب)
- FPN، Mask R-CNN، YOLO و… برای تشخیص عیب بهصورت Object Detection
- وقتی میخواهید مکان عیب (Bounding Box / Mask) را روی قطعه مشخص کنید.
CNNها در تشخیص عیوب سطحی با الگوهای قابل مشاهده، بسیار قویاند. اما وقتی پیچیدگی فضایی و ساختاری بالا میرود – یا روابط بلندبرد (Long-range dependencies) مهم میشوند – معماریهای Attention محور وارد بازی میشوند.
شبکههای مبتنی بر Attention و Vision Transformer
Vision Transformer (ViT) و مدلهای مشابه، تصویر را به پچهای کوچک تقسیم میکنند و با مکانیزم Attention یاد میگیرند که کدام بخشهای تصویر برای تصمیمگیری مهمترند.
مزایا در حوزه بازرسی:
- بهتر دیدن روابط غیرمحلی: مثلاً یک الگوی عیب که در چند نقطه پراکنده است.
- انعطافپذیری در ترکیب با سایر اطلاعات (مثلاً Text، Sensor data).
معماریهای ترکیبی مثل Swin Transformer یا نسخههای CNN + Attention (مانند ResNet با بلوکهای SE یا CBAM) بهطور ویژه در صنعت محبوب شدهاند، چون:
- هم از قابلیت محلی CNN استفاده میکنند.
- هم از درک جهانیتر Attention بهره میبرند.
مدلهای هیبریدی و چندشاخه (Multi-branch)
در بازرسی واقعی، اغلب یک نوع تصویر نداریم:
- تصویر RGB
- تصویر Infrared
- تصویر X-ray
- عمق (Depth) از Lidar یا Structured Light
- یا حتی دادههای زمانی (Sequence) از یک قطعه در طول خط
مدلهای Multi-branch طراحی میشوند تا:
- هر نوع داده را در یک شاخه جدا پردازش کنند.
- در یک لایه Fusion (Late / Mid / Early Fusion) اطلاعات را ترکیب کنند.
- تصمیم نهایی را با در نظر گرفتن همه Modalها بگیرند.
این معماریها برای تشخیص عیوب پیچیده ساختاری (مثلاً داخل قطعه، یا ترکیب سطح و ساختار) بسیار مؤثرند.
استراتژیهای تشخیص عیوب: طبقهبندی، تشخیص، سگمنتیشن، آنومالی
طبقهبندی (Classification)
در این روش، ورودی سیستم یک تصویر از قطعه یا بخشی از آن است و خروجی میتواند بهصورت یک برچسب ساده مانند سالم یا معیوب، یا تشخیص نوع عیب شامل خراش (Scratch)، ترک (Crack)، فرورفتگی (Dent) و موارد مشابه ارائه شود. این رویکرد زمانی ایدهآل است که محل دقیق عیب اهمیت چندانی نداشته باشد و تنها وجود عیب یا دستهبندی کلی آن برای تصمیمگیری کفایت کند.
تشخیص شیء (Object Detection)
در این روش، خروجی سیستم شامل جعبههای تشخیصگر (Bounding Box) بههمراه کلاس یا نوع هر عیب است. این رویکرد زمانی کاربردی است که لازم باشد محل دقیق عیب روی قطعه مشخص شود؛ چه برای استفاده یک ربات در فرآیند تعمیر یا جداسازی، چه برای راهنمایی اپراتور و چه برای ثبت و گزارشگیری دقیق در سیستمهای کنترل کیفیت.
سگمنتیشن (Segmentation)
در این روش، خروجی بهصورت یک ماسک پیکسلی ارائه میشود که در آن وضعیت هر پیکسل بهطور دقیق مشخص میکند سطح سالم است یا معیوب. این شیوه زمانی مناسب است که عیبها گسترده، نامنظم یا دارای مرزهای پیچیده باشند، یا زمانی که نیاز به برآورد دقیق مساحت، شکل یا حتی حجم تقریبی ناحیه معیوب وجود دارد.
تشخیص ناهنجاری (Anomaly Detection / Novelty Detection)
در این رویکرد، تمرکز اصلی سیستم بر یادگیری الگوی «سالم» قطعه است و هرگونه انحراف معنیدار از این الگو بهعنوان نشانهای از وجود عیب تشخیص داده میشود. چنین روشی برای موقعیتهایی ایدهآل است که عیوب بسیار نادر هستند، نمونههای کمی از آنها در دسترس است، یا انواع احتمالی عیب از پیش بهطور کامل شناخته نشدهاند. در بسیاری از سیستمهای صنعتی پیشرفته، معمولاً ترکیبی از این روشها بهکار گرفته میشود؛ به این صورت که ابتدا یک ماژول تشخیص ناهنجاری (Anomaly Detection) بررسی میکند آیا قطعه رفتار یا الگوی غیرعادی دارد یا خیر. اگر قطعه مشکوک تشخیص داده شود، سپس ماژولهای دقیقتر مانند Detetion یا Segmentation فعال میشوند تا نوع عیب، موقعیت دقیق آن و گستره آسیب بهطور کامل مشخص شود.
چالش اصلی: کمبود داده عیبدار
بزرگترین چالش عملی: داده عیبدار کم است.
بهطور طبیعی، در یک خط تولید سالم، ۹۹٪ قطعات سالماند؛ ۱٪ – و خیلی وقتها کمتر – معیوباند.
این باعث میشود:
- کلاس معیوب بسیار نامتوازن (Imbalanced) باشد.
- مدل به سمت «همه چیز سالم است» Bias پیدا کند.
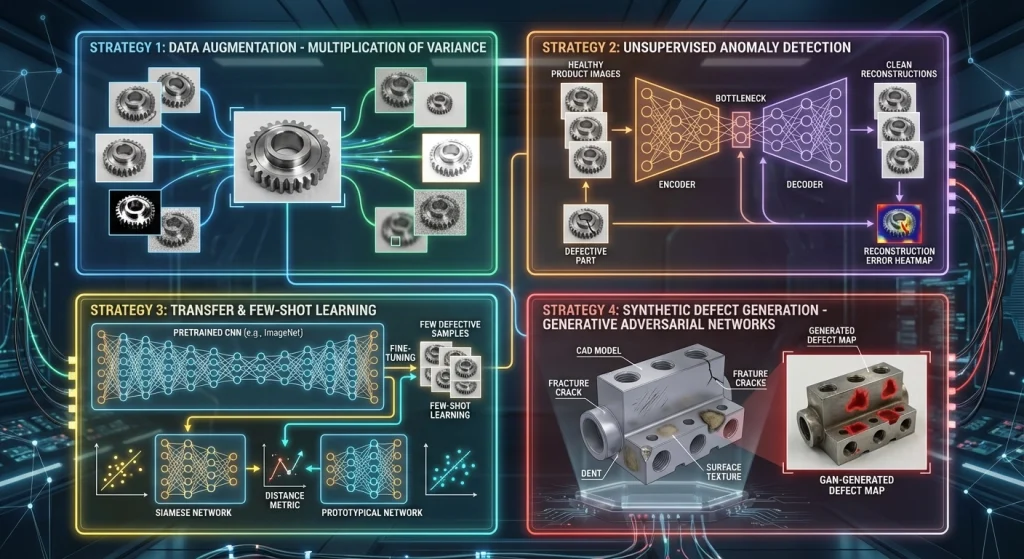
راهحلها
Data Augmentation
هدف: افزایش تنوع داده بدون جمعآوری نمونههای واقعی بیشتر.
- Rotation، Shift، Scaling
- تغییر روشنایی، کنتراست و نویز
- Blur برای شبیهسازی تغییر فوکوس
- Cutout، Mixup و روشهای پیشرفتهتر
Augmentation باید فیزیکی و منطقی باشد. مثلاً چرخش ۱۸۰ درجه برای قطعات متقارن مناسب است اما برای قطعات جهتدار ممکن است غیرواقعی باشد.
Anomaly Detection
در بسیاری از خطوط تولید، داده سالم زیاد است ولی نمونه عیب کم. بنابراین مدل ابتدا الگوی «سالم» را یاد میگیرد.
- Autoencoder
- Variational Autoencoder
- Flow-based models
- Self-supervised models
اگر بازسازی تصویر ضعیف باشد یا در فضای ویژگی از داده سالم فاصله بگیرد، سیستم آن را ناهنجار تشخیص میدهد.
Transfer & Few-shot Learning
استفاده از مدلهای از پیش آموزشدیده و تنظیم آنها روی دیتای محدود صنعتی.
- Transfer Learning (Fine-tuning)
- Siamese Networks
- Prototypical Networks
- Meta-learning
این روشها به مدل اجازه میدهند با تعداد بسیار کمی نمونه از هر عیب، کلاسهای جدید را یاد بگیرد.
Synthetic Data
تولید داده مصنوعی با استفاده از شبیهسازی یا مدلهای تولیدی.
- رندر سهبعدی قطعات
- GAN و Diffusion برای ایجاد خراش و ترک
- ترکیب داده واقعی و Synthetic
- Domain Adaptation
داده مصنوعی باید از نظر آماری و بصری به دنیای واقعی نزدیک باشد تا مدل در محیط واقعی عملکرد خوبی داشته باشد.
قبل از انتخاب مدل باید مسئله بهصورت دقیق تعریف شود.
هدف سیستم چیست؟
- حذف قطعات معیوب
- درجهبندی کیفیت (Grade A/B/C)
- ارسال هشدار به اپراتور
باید مشخص شود چه انواع عیبی برای کسبوکار مهم هستند و کدام عیوب کوچک آنقدر بحرانی نیستند که باعث Reject قطعه شوند.
همچنین شاخصهای عملکردی سیستم (KPI) باید مشخص شوند:
- حداکثر False Reject Rate قابل قبول
- حداکثر Missed Defect Rate
- سرعت مورد نیاز سیستم (FPS یا قطعه در ثانیه)
این مرحله مستقیماً روی طراحی برچسبها، ساختار مدل و Threshold تصمیمگیری تأثیر میگذارد.
در ابتدای کار بهتر است سختافزار نهایی شامل دوربین، لنز و نور تا حد امکان نزدیک به شرایط واقعی خط تولید انتخاب شود.
تغییر سختافزار در مراحل بعدی میتواند باعث بیاستفاده شدن بخش بزرگی از دیتاست شود.
دادهها باید در شرایط متنوع جمعآوری شوند:
- تنوع نور در محدوده شرایط واقعی خط تولید
- تنوع Batchهای تولید
- تفاوت اپراتورها و ماشینها
در مرحله برچسبگذاری:
- برای Segmentation نیاز به ماسک پیکسلی است که تهیه آن زمانبر است.
- در بسیاری از پروژهها ابتدا با Bounding Box شروع میشود.
همچنین بهتر است چند برچسبگذار مستقل بخشی از داده را برچسب بزنند تا میزان Consistency بررسی شود.
چند عامل مهم در انتخاب مدل وجود دارد:
- سرعت استنتاج (Inference)
- پیچیدگی عیوب
- محدودیت سختافزاری
برای Edge Device با حافظه محدود معمولاً از مدلهای سبک مانند MobileNet یا EfficientNet-Lite استفاده میشود.
در سرورهای GPU قدرتمند میتوان از مدلهای بزرگتر مانند ViT یا Swin Transformer استفاده کرد.
در بسیاری از پروژههای صنعتی معماریهای زیر نتایج بسیار خوبی داشتهاند:
- Classification: ResNet50 / EfficientNet
- Detection: YOLOv5 / YOLOv8 / EfficientDet
- Segmentation: U-Net / DeepLab / SegFormer
تقسیم دادهها به مجموعههای Train، Validation و Test باید بهدرستی انجام شود.
اگر دادههای یک Batch تولید هم در Train و هم در Test قرار بگیرند، Overfitting پنهان میشود.
تحلیل خطا بسیار مهم است:
- False Positive — قطعه سالم بهعنوان معیوب
- False Negative — قطعه معیوب بهعنوان سالم
در مرحله بهینهسازی میتوان از تکنیکهای زیر استفاده کرد:
- Class Weighting برای عدم توازن دادهها
- Focal Loss برای تمرکز روی نمونههای سخت
- Fine-tuning تدریجی لایههای شبکه
پس از آموزش، مدل باید در محیط واقعی اجرا شود.
- On-edge: اجرای مدل روی دستگاه نزدیک دوربین مانند Industrial PC یا Nvidia Jetson. مزیت آن latency پایین و استقلال از شبکه است.
- On-premise Server: چند خط تولید به یک سرور مرکزی GPU متصل میشوند.
- Cloud: انعطافپذیری بالا اما در صنایع حساس استفاده از آن محدودتر است.
در مرحله استقرار ایجاد یک Feedback Loop بسیار مهم است:
- ثبت تصاویر و تصمیمهای مدل
- ثبت تصمیم نهایی اپراتور
- استفاده از این دادهها برای Re-training مدل
معیارهای ارزیابی: چرا Accuracy بهتنهایی گمراهکننده است؟
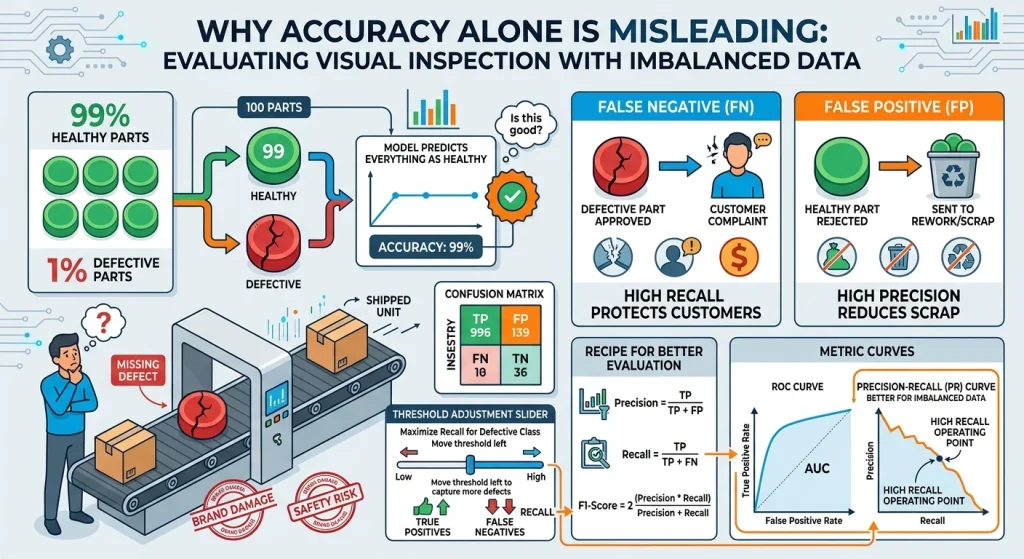

فرض کنید:
- ۹۹٪ قطعات سالماند.
- ۱٪ معیوباند.
مدلی که همیشه بگوید «سالم» است، Accuracy = 99٪ دارد،
ولی از دید کیفیت، فاجعه است.
در بازرسی صنعتی، هزینه این دو نوع خطا بسیار متفاوت است:
- False Negative (عیبدار، سالم تشخیص داده شده):
- قطعه بد به مشتری میرسد، ریسک ایمنی، آسیب برند، Recall.
- False Positive (سالم، معیوب تشخیص داده شده):
- اسکرپ یا Rework غیر ضروری، هزینه تولید.
بنابراین باید از معیارهای زیر استفاده کنید:
- Precision / Recall / F1-score
- Recall برای کلاس معیوب معمولاً بسیار مهم است (نباید عیب را از دست بدهیم).
- ROC Curve و AUC
- کمک برای انتخاب Threshold.
- PR Curve (Precision-Recall)
- در دادههای Imbalanced بهتر از ROC است.
- Confusion Matrix
- دید شفاف به توزیع خطاها.
استراتژی رایج:
- ابتدا Threshold را طوری تنظیم کنید که Recall روی کلاس معیوب بسیار بالا باشد (مثلاً ۹۹٪)، و بعد تلاش کنید با بهبود مدل و داده، Precision را بالا ببرید تا False Positiveها کمتر شوند.
چالشهای دنیای واقعی: نور، تنوع قطعات، Drift و تغییرات خط تولید
تغییر نور
- لامپها به مرور زمان تغییر شدت میدهند.
- گرد و غبار روی لنز، انعکاسهای جدید ایجاد میکند.
- بعضی اپراتورها کادر را کمی جابهجا میکنند.


- تنوع قطعات
- Lotهای تولیدی مختلف، کمی رنگ یا بافت متفاوت دارند.
- تامینکنندههای مختلف مواد اولیه، ظاهر را تغییر میدهند.
Data Drift / Concept Drift
- با گذشت زمان، الگوی عیوب تغییر میکند؛ ماشینآلات فرسوده میشوند، نوع عیبها عوض میشود.
برای مدیریت این چالشها:
- طراحی سیستم نور ثابت و کنترلشده (Light enclosure، استفاده از LED ثابت و پایدار).
- استفاده از Calibration دورهای برای دوربین و نور.
- جمعآوری و Label کردن دورهای دیتا از خط تولید و بهروزرسانی مدل (MLOps برای بینایی ماشین).
- استفاده از تکنیکهای Domain Adaptation وقتی شرایط تولید جدید با Training data فرق زیادی دارد.

بهترینعملها (Best Practices) در پروژههای صنعتی
Pilot واقعی
با یک ایستگاه، یک نوع قطعه و یک عیب مهم شروع کنید. اما سیستم را حتماً در محیط واقعی خط تولید پیادهسازی کنید، نه فقط در آزمایشگاه.
کیفیت داده
در بازرسی صنعتی، کیفیت داده حدود ۶۰ تا ۷۰ درصد موفقیت پروژه را تعیین میکند. به جای تمرکز زودهنگام روی مدل پیچیده، روی جمعآوری و تمیز بودن دادهها سرمایهگذاری کنید.
Human‑in‑the‑loop
در مراحل اولیه تصمیم نهایی باید با اپراتور یا کارشناس باشد. سیستم باید امکان اصلاح تصمیمهای مدل را فراهم کند تا دادهها وارد چرخه آموزش بعدی شوند.
Monitoring و Logging
ثبت تصاویر، خروجی مدل، تصمیم اپراتور و وضعیت ماشین ضروری است. اندازهگیری مداوم KPIها مانند Reject Rate و Missed Defect برای کنترل عملکرد سیستم حیاتی است.
Explainability
با استفاده از روشهایی مانند Grad‑CAM یا Heatmap میتوان نشان داد مدل روی کدام بخش تصویر تمرکز کرده است. این موضوع در پذیرش سیستم توسط مهندسان کیفیت بسیار مؤثر است.
Integration با تولید
سیستم AI باید با فرآیند تولید هماهنگ باشد. از ابتدا برای اتصال به سیستمهایی مانند MES، ERP و Traceability برنامهریزی کنید.
- الزامات آنها را بفهمید
- محدودیتهای فنی خط را بشناسید
- از ابتدا برای Integration برنامه داشته باشید (MES، ERP، سیستمهای Traceability)
آینده بازرسی بصری پیشرفته: از Self-supervised تا سیستمهای خودتطبیقی
چند روند مهم که بازرسی بصری پیشرفته را در سالهای آینده عوض میکند:
Self-supervised Learning
ورودی: تصویری از قطعه یا بخشی از آن خروجی: سالم / معیوب، یا نوع عیب (Scratch، Crack، Dent، …) مناسب برای: وقتی محل دقیق عیب مهم نیست، فقط وجود یا نوع کلی آن اهمیت دارد.
Foundation Models برای بینایی صنعتی
مدلهای بزرگ بینایی که روی دیتاستهای عظیم صنعتی (نه صرفاً ImageNet) پیشآموزش داده شدهاند. این مدلها میتوانند با داده بسیار کم برای یک خط تولید خاص Adapt شوند.
سیستمهای خودتطبیقی (Adaptive Inspection Systems)
مدل، بهطور آنلاین خود را با تغییرات خط Adjust میکند. استفاده از Feedback دائمی اپراتورها و سنسورهای خط. ادغام با مدلهای پیشبینانه نگهداشت (Predictive Maintenance) تا از روی تغییر الگوی عیوب، مشکلات ماشین را زودتر تشخیص دهد.
ترکیب چند Modal (Multimodal)
استفاده همزمان از تصویر، صدا، لرزش، دما، دادههای PLC و… برای تشخیص عیوب پیچیده. این، دید ۳۶۰ درجه از وضعیت کیفیت و سلامت سیستم میدهد.
استفاده از مدلهای مولد (Generative AI)
برای شبیهسازی سناریوهای نادر عیب. برای ایجاد داده آموزشی برای حالات Failure که در دنیای واقعی هزینهبر یا خطرناکاند.

جمعبندی و توصیههای کاربردی برای شروع
بازرسی بصری پیشرفته با تکیه بر تکنولوژی یادگیری عمیق، از یک «آپشن جذاب» به یک «نیاز استراتژیک» برای بسیاری از صنایع تبدیل شده است.
چند نکته کلیدی که میتواند مثل چکلیست برای شما عمل کند:
- مسئله را دقیق تعریف کنید
- چه عیبی؟ چه سطح حساسیتی؟ چه سرعتی؟ چه KPIهایی؟
- زودتر به داده فکر کنید تا به مدل
- برنامهریزی برای جمعآوری، Labeling، و نگهداری دیتاست.
- یک معماری معقول، نه لزوماً عجیبوغریب انتخاب کنید
- اغلب معماریهای استاندارد (ResNet، U-Net، YOLO) با داده خوب، نتایج عالی میدهند.
- به Imbalanced بودن عیوب احترام بگذارید
- از تکنیکهایی مثل Anomaly Detection، Augmentation، Transfer Learning استفاده کنید.
- چرخه کامل را ببینید: از آموزش تا استقرار و بازآموزی
- MLOps برای بینایی ماشین را در طراحی سیستم لحاظ کنید.
- پذیرش سازمانی را فراموش نکنید
- کیفیت، تولید، IT، و اپراتورها باید در طراحی درگیر باشند تا سیستم واقعاً استفاده شود، نه اینکه فقط روی پاورپوینت قشنگ به نظر برسد.
گام بعدی شما در تحول بازرسی بصری
سوالات متداول درباره بازرسی بصری پیشرفته
در این بخش به رایجترین سوالات درباره پیادهسازی، مزایا، الزامات فنی و کاربردهای صنعتی بازرسی بصری پیشرفته مبتنی بر یادگیری عمیق پاسخ دادهایم.